
如果是很早期開始接觸 skills 的使用者,可能已經很習慣創造自己所需的 SKILL.md,甚至可能有一個 skill 是「專門用來創造 skill」,加速我們開發的進程。
三月初時,Anthropic 發布了名為 skill-creator 的 plugin,讓非工程師背景的 CC 使用者,也能更輕鬆地針對自己的需求,迅速打造出專屬的 skill。
你可能會想說:「我自己會寫 skill,還需要 skill-creator 嗎?」
相比自己手刻一個 SKILL.md,透過 /skill-creator 指令開發的過程,CC 在得知使用者的需求後,實際上會經歷下面幾個階段:
- 定義技能
- 撰寫技能
- 測試
- 評估
- 改進
- 重複
- 打包
確保產出的 skill 是可用且「優於基礎模型的直接回饋」,白話一點——「如果直接問 AI 都可以得到很好的答案,那這個 skill 還有存在的必要嗎?」
skill 有兩種
斯斯有幾種?(冷笑)
根據 Anthropic 官方說明,skill 通常可以分成 Capability uplift skills(能力提升型)與 Encoded preference skills(偏好流程型)兩種類型。
Capability uplift skills 能力提升型
主要幫助基礎模型(Opus、Sonnet 等)做到「本來做不到」或是「做得不穩定」的任務。
例如「創建文件」這類型的任務,很容易受到 prompt(提示詞)的影響,而造成產出的文件內容有巨大差異,透過 skills 可以讓整體品質更為一致。
Encoded preference skills 偏好流程型
這類型是 skill 主要不是提升 Claude 本身的能力,而是讓 Claude 依循「某個特定的流程」依序完成任務。
例如團隊在審查 NDA 文件時,有固定需要確認的準則,透過這類型 skill 可以讓 Claude 依據固定標準逐步檢查。
Anthropic 之所以會將 skill 這樣進行分類,是因為這兩種在測試、檢核上要顧及的面向不同。
能力提升型 skill 有可能因為時間推演,模型本身能力逐漸變強,而變得「不再需要」,畢竟內建有的能力,再透過 skill 裝備,反而顯得多此一舉。
偏好流程型 skill 不會因為模型能力而有所差異,所以驗證重點在於「是否忠實完成我們期待的工作流程」。
skill-creator 強在哪
在文章的開始有提到,使用 /skill-creator 除了撰寫 skill 內容,也會進行測試、評估,這正是官方 plugin 的價值所在。
/Skill-creator 在執行過程中會幫我們撰寫 evals(評估測試),用來確認 Claude 在特定 prompt 下是否能產出符合我們預期的成果,一如平時撰寫軟體測試會發生:
- 定義測試用的 prompt(必要時搭配檔案)
- 描述「什麼是好的結果」
- 由 skill-creator 判斷這個 skill 是否達標
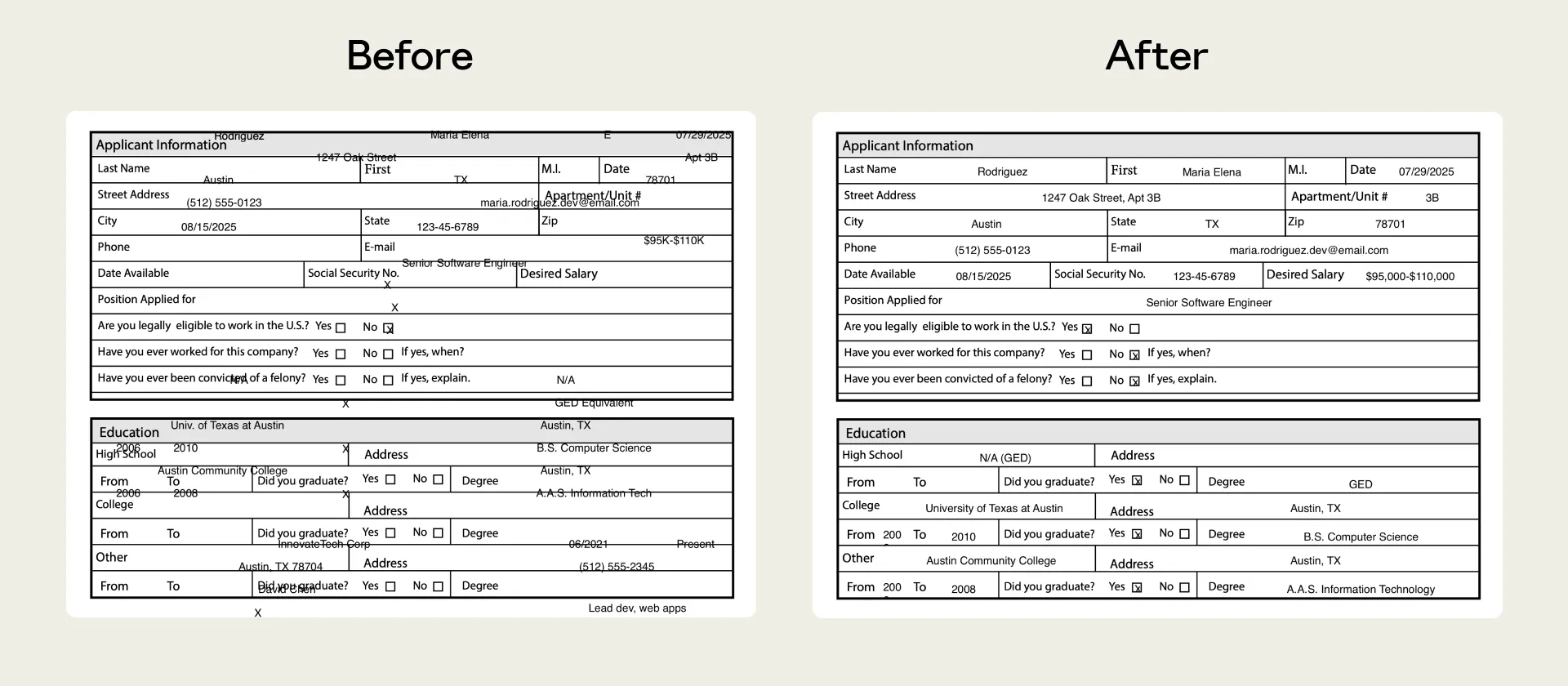
Anthropic 以自家開發的 PDF skill 為例,過往這個 skill 處理「不可編輯的 PDF 檔案」時,表現得差強人意,因為我們預期 Claude 必須把文字放到「正確欄位」,但這些表單沒有欄位(field)可以參考定位。
透過 skill-creator 的 eval 過程,找出修正方案——改為依據「從 PDF 擷取出的文字座標」來定位內容,而後使用這個 PDF skill 能讓 Claude 定位更加準確。
Evals 的用途
Evals(評估測試)可以為開發帶來許多好處,但在開發 skill 中,有兩個非常重要的原因:「偵測 skill 品質是否退化」和「判斷模型能力是否已經超越該 skill」。
偵測品質退化(quality regressions)
隨著模型與其相關基礎設施持續變化,上個月還很好用的 skill,這個月使用起來卻可能不如預期。
所以在新模型上執行 evals,能夠讓我們「提早發現這些變化(退化)」,並在影響團隊開發前就取得警訊,並進行調整優化。
判斷模型能力是否已經超越該 skill
這點前面也說過了,如果基礎模型在「沒有載入該 skill」的情況下,就已經能通過 evals,那代表——「這個 skill 很可能已經被模型內建吸收」,也就沒有要另外存在的必要了。
評比模式 Benchmark mode
在軟體開發的世界裡,「很好用」、「有進步」都是很虛無飄渺的形容詞,大家想知道的是「加快了幾秒」、「用了多少 token」,有數字有真相。
而我們透過 Benchmark <skill-name> with and without loaded the skill. Show me side-by-side results 類似的 prompt,讓 Claude 產出有關「eval 通過率」、「執行時間」、「token 使用量」等相關數據的評比報告,比較有沒有 skill 時的表現差異。
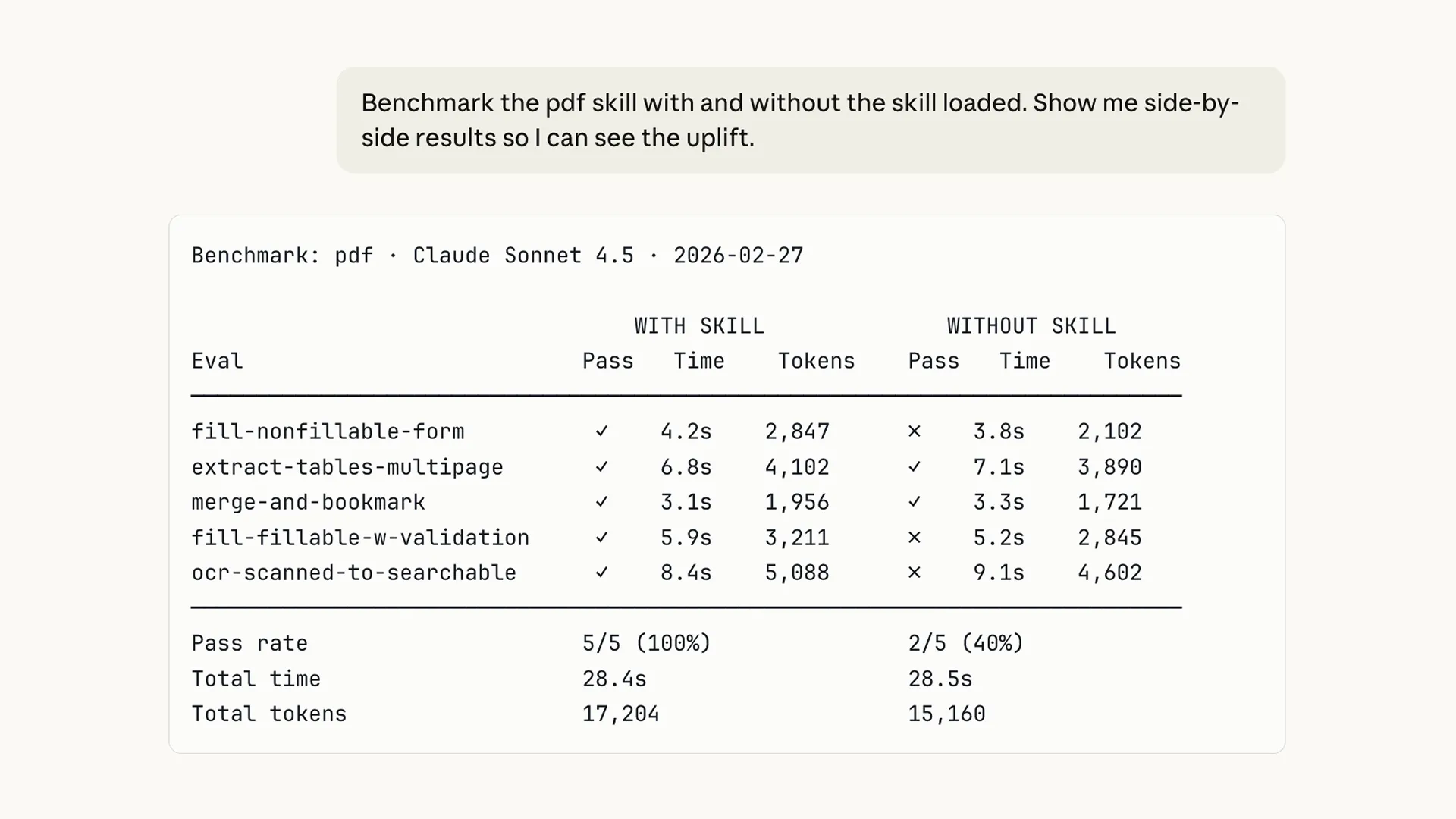
除了將報告存放在本機,我們甚至可以將這份報告整合進個人 dashboard 做可視化分析,或是接入 CI 系統(例如 GitHub Actions)做自動化測試。
skill-creator 如何有效率地進行測試評估
在 skill-creator 的原始碼中,可以發現有三個分別為 analyzer(分析者)、comparator(比較者)、grader(評分者)的 agent,所以當 eval 任務開始進行時,每個 agent 會在各自獨立的環境裡進行評量,除了加快測試速度,也可以統計 agent 各自所需要的 token 使用量與執行時間。
skill-creator 的原始碼 repo
skill-creator 如何確認 skill 在正確的時機被觸發
剛開始使用 skill 會以為我們只能透過手動輸入 /某某skill 指令,才能執行指定的 skill,不過在〈寫 skills 該注意什麼事〉的「描述觸發條件」中,有說到 SKILL.md 中的 description 其實是用來「描述這個 skill 的觸發條件」,那 skill-creator 是怎麼評估、確認創造出來的 skill 能被正確觸發呢?
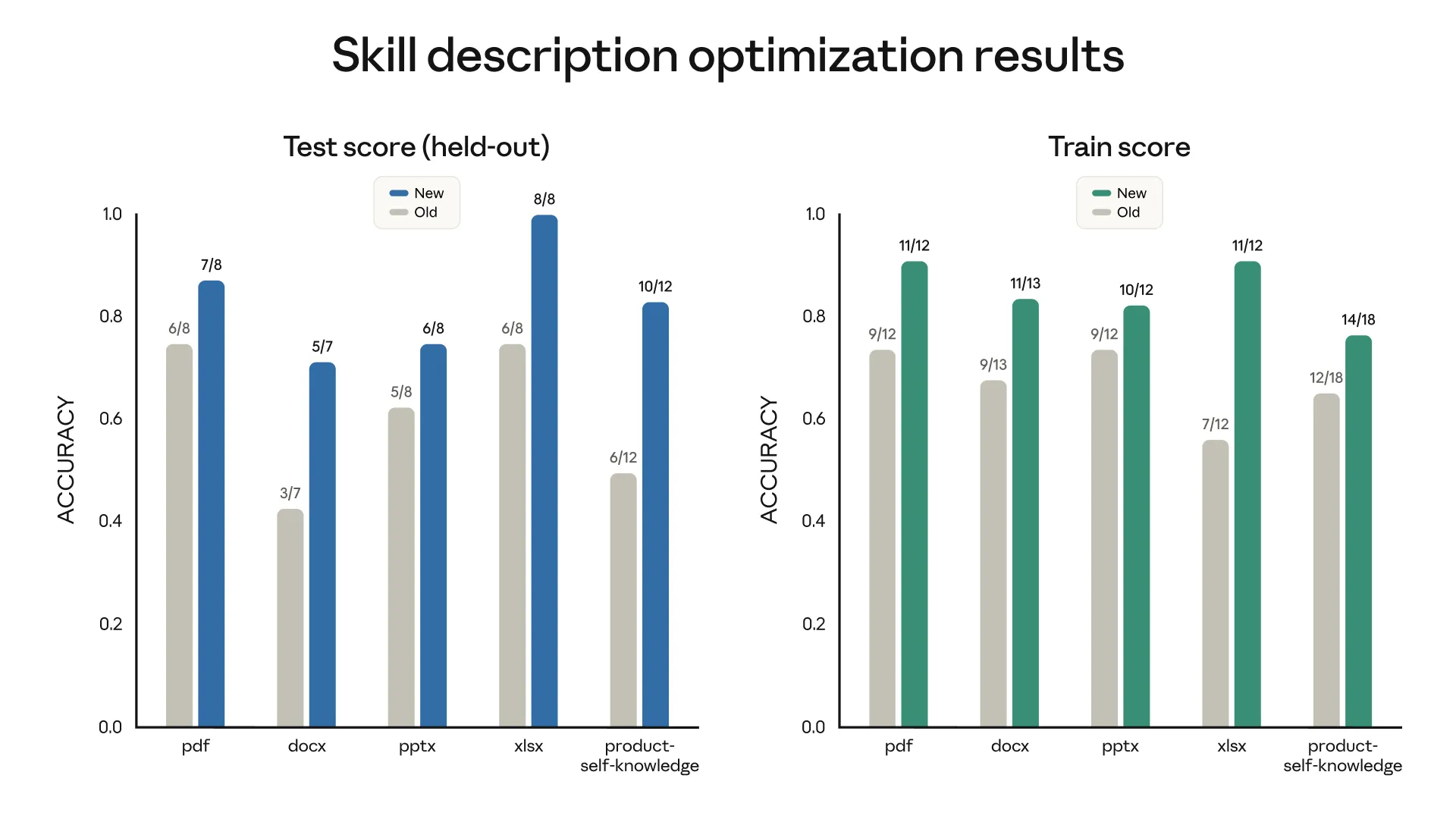
skill-creator 會先分析 description,然後生成數個實際的 prompt 進行測試,並且根據誤觸(false positives)與漏觸(false negatives),提出優化建議。
隨著模型的理解能力越來越強,我們可以清楚地感知到「skill」與「spec」的界線已經越來越模糊。
雖然在 SKILL.md 中,本質上還是一份「實作計畫」,我們在裡面明確告訴 Claude「要怎麼做」,但也可以發現在使用 /skill-creator 的過程,更多時候只需要用自然語言描述「這個 skill 要做什麼」,模型本身已能自己推導出「要怎麼做」、「怎麼做能更好」。
感覺在不遠的未來,skill 的本質可能會從「一份詳細的操作說明」變成「一組可驗證的行為定義」。
參考資料:Claude Blog - Improving skill-creator: Test, measure, and refine Agent Skills